


System Design Simplified: A Beginner's Guide to Everything You Need to Know (Part 9.1)
Master the Basics of System Design with Clear Concepts, Practical Examples, and Essential Tips for Beginners.


Hello everyone, Lorenzo here! (As always, running a bit behind schedule—but I promise, this one will be worth the wait!)
How’s everyone doing? Hope you’re all great because today, we’re diving deep into one of the most crucial trade-offs in distributed systems: consistency. And no, I’m not talking about the kind you need at the gym—I mean consistency in computer science.
We’ll be exploring two fundamental approaches: Strong vs. Eventual Consistency. What are they? When should you choose one over the other? What trade-offs do they bring in terms of performance, scalability, and fault tolerance?
Expect insights, real-world examples, and a bit of theory (but don’t worry, I’ll keep it engaging!). Whether you’re designing a distributed database, working with microservices, or just curious about the CAP theorem in action, this will be a deep but fun dive.
So: ready, set, go…. let’s jump in! 🚀
Choosing Between Strong vs. Eventual Consistency: A Tale of Two Stories
In our modern software architectures, distributed systems have increasingly become the backbone of scalability, availability, and resilience. Microservices, in particular, have revolutionized the way we design and deploy applications, breaking down monolithic structures into independent, self-sufficient services. However, with this shift comes a fundamental challenge, which is not so easy to overcome: data consistency.
How do we ensure that many dispersed services maintain accurate and reliable data? What trade-offs do we make between performance, fault tolerance, and correctness? How to properly manage the hidden complexities of those type of systems? This article is designed with a core concept in mind: to help architects, developers, and technology decision-makers navigate the complexity of consistency models—with a special focus on eventual consistency vs. strong consistency.
Why Consistency Matters in Distributed Systems
At its core (in simple terms), consistency in distributed computing means ensuring that data across different nodes eventually reaches a correct state. However, achieving this is not trivial—especially in environments prone to network failures, high latency, and partitioning issues.
The CAP theorem tells us that we must make trade-offs between Consistency, Availability, and Partition Tolerance, making it essential to choose a consistency model that aligns with system’s basic requirements.
Eventual Consistency (as we will see, it is used in systems like DynamoDB, Apache Cassandra) allows updates to propagate asynchronously, improving availability but leading to temporary inconsistencies. To counteract this, robust conflict resolution mechanisms are required.
Strong Consistency (seen in databases like Spanner, CockroachDB) ensures that all nodes always have the latest data available, simplifying reasoning about the system but introducing performance overhead (and some other related issues) due to synchronization delays.
Both models have their pros and cons, directly influencing system design decisions—especially when building complex applications in microservices, financial systems, eCommerce, and real-time analytics.
In these domains, the cost of inconsistency varies depending on the specific business requirements and the acceptable trade-offs between performance, availability, and data accuracy.
The Trade-Offs and Real-World Impact
While microservices enable flexible deployment and continuous integration, inconsistencies in data synchronization can lead to unexpected failures, duplicated transactions, or loss of user trust. Imagine an online marketplace where an order status fails to update in real time—leading to double orders or incorrect inventory tracking.
Balancing data consistency with system performance requires careful design patterns, synchronization strategies, and business logic adaptation. This article (split in 2 parts) will explore:
Theoretical foundations of consistency models and their evolution throughout time
Practical trade-offs between eventual and strong consistency
Real-world examples from distributed databases, microservices, and event-driven architectures
How frameworks like CAP, PACELC, and AI-driven adaptive consistency influence modern system design
User experience and the psychology of data synchronization—why visible inconsistencies matter
By the end, you’ll have a comprehensive understanding of how consistency choices impact distributed applications and how to make informed decisions that balance efficiency, reliability, and scalability. Let’s dive in!
Historical Evolution of Consistency Models
In the early years of distributed computing, the vision was ambitious yet deceptively simple—distribute workloads across multiple machines to achieve higher scalability, fault tolerance, and performance.
Instead of relying on a single powerful computer, engineers sought to harness the power of many—a network of interconnected nodes working together. The promise was clear: better resource utilization, increased availability, and improved resilience to failures.
However, as these systems grew in scale and complexity, a fundamental question emerged:
How do we ensure that all nodes in the system see the same version of data, even when updates happen concurrently across different locations?
Unlike centralized databases, where essentially a single authoritative source maintains the definitive state of data, distributed systems operate in a world of asynchronous communication, unreliable networks, and unpredictable failures. This shift introduced a new class of data consistency challenges that engineers had never encountered before.
The Hidden Cost of Distribution
At first, the benefits of distributed computing seemed to outweigh any possible drawbacks. More machines meant more processing power, and if one node failed, the others could take over seamlessly. But as these systems expanded, strange and unexpected problems started to arise very soon.
Imagine for a moment a financial trading system where multiple users submit transactions to different nodes at nearly the same time. One trader might see a stock price update immediately, while another, using a different server, might see an outdated version. Who is right? And what happens when two traders buy the last available share simultaneously from different nodes?
This has an obvious impact on money management, potential profitability, and overall risk/reward strategies. In the case of global financial institutions, such inconsistencies could lead to losses of millions—if not tens of millions—of dollars on a single trade.
These inconsistencies became a serious obstacle to trust and reliability in distributed systems. Engineers quickly realized that simply distributing data across multiple nodes wasn’t enough AT ALL—they needed a way to keep that data consistent across all machines, even when failures and network delays occurred.
This challenge manifested in several ways:
1. Stale Reads – The Illusion of the Past
Since data was replicated across multiple nodes, some users would occasionally read outdated values before updates had propagated to all machines.
Example: A user updates their shipping address in an e-commerce platform, but when they check their order status moments later, it still shows their old address. Why? Because they were routed to a server that had not yet received the latest update.
Key Question: Should systems prioritize speed and availability, even if it means temporarily showing outdated data? Or should they wait for synchronization, sacrificing speed for consistency?🎯
2. Lost Updates – The Vanishing Writes
When multiple users updated the same piece of data at nearly the same time, one update might silently overwrite another, leading to lost information.
Example: Two employees edit the same document stored in a distributed file system. One saves their changes at 10:01 AM, and another at 10:02 AM—but because updates were processed independently, the first set of changes is lost forever.
Key Question: How should distributed systems merge conflicting updates? Should the latest write always win, or should both changes be preserved in some way?
3. Conflicting Operations – The Diverging Realities
If two nodes update the same data independently, but without knowledge of each other, their changes might contradict each other, leading to inconsistent states.
Example: A banking system with two separate database servers allows a customer to withdraw $500 from two different ATMs simultaneously. If the withdrawals are processed on different nodes without immediate synchronization, the system may fail to detect that the account should be overdrawn.
Key Question: How should a distributed system resolve conflicts when two versions of the same data exist? Should one node be the “leader,” or should all nodes try to reach a consensus?
The Need for a New Approach
In the face of these massive challenges, early distributed system designers had to confront an uncomfortable truth:
A distributed system cannot simply assume that all nodes will always have an up-to-date and consistent view of data.
Unlike traditional single-node databases, where consistency was relatively easy to enforce, distributed environments introduced delays, failures, and conflicts that had to be managed explicitly. Engineers needed to rethink how data was stored, synchronized, and reconciled across multiple machines.
This realization sparked a new wave of research into formal consistency models, leading to some of the most important breakthroughs in distributed computing ever made. Researchers and practitioners began classifying and structuring data consistency guarantees, setting the stage for modern distributed database architectures.
Should all writes be instantly visible to all users, or is some delay acceptable?
Should updates be coordinated through a central leader, or should every node have equal authority?
How do we balance performance, availability, and consistency when network failures occur?
These questions shaped the evolution of distributed systems, leading to the development of replication protocols, synchronization mechanisms, and conflict resolution strategies that form the foundation of modern cloud-based architectures.
Laying the Groundwork for Future Innovations
As we briefly said before, the work done during this era created the foundation for some of the most critical theoretical and practical advancements in distributed systems:
CAP Theorem (Eric Brewer, 2000) – Formalized the fundamental trade-offs between Consistency, Availability, and Partition Tolerance, forcing system designers to prioritize certain properties based on their needs.
Eventual Consistency Models – Allowed distributed databases to tolerate temporary inconsistencies in exchange for better latency and availability.
Consensus Protocols (Paxos, Raft) – Provided a way for nodes to agree on a single version of truth, even in the presence of failures and network partitions.
Hybrid Consistency Models – Enabled systems to selectively enforce strict consistency for critical data while allowing eventual consistency for less crucial information.💡
With these developments, distributed systems moved from being ad-hoc and unpredictable to structured and well-understood. The insights gained from these early challenges continue to influence how modern cloud databases, blockchain networks, and large-scale web applications handle data consistency at global scales.
But one question still remains unanswered:
Is perfect consistency ever truly achievable in a distributed system, or must we always make trade-offs?
As new architectures continue to emerge, and as AI-driven adaptive consistency models gain traction, the journey toward fully autonomous, self-regulating distributed systems is only just beginning.
Key Milestones in Consistency Theory
One of the most significant theoretical breakthroughs in distributed systems was the CAP theorem, proposed by Eric Brewer in 2000. CAP introduced a fundamental limitation in distributed computing, summarized below:
A distributed system can provide at most two out of three guarantees at any given time:
Consistency (C): All nodes always have the same, up-to-date data.
Availability (A): Every request receives a response, even if some nodes are down.
Partition Tolerance (P): The system continues to function even when network partitions occur.
When a network partition (temporary communication failure) occurs, a system must choose between consistency and availability. This meant that system designers needed to prioritize one aspect over the other based on their application’s needs:
CP Systems (Consistency + Partition Tolerance) – Prioritize strong consistency but may sacrifice availability during partitions. (e.g., traditional relational databases)
AP Systems (Availability + Partition Tolerance) – Prioritize availability, accepting eventual consistency in the process. (e.g., NoSQL databases like DynamoDB, Cassandra)
While CAP provided a theoretical framework, it was still a simplification of something bigger. It failed to take into account things like latency trade-offs in consistency decisions. In response, Daniel Abadi (2012) introduced the PACELC theorem, which essentially extended CAP by stating:
Even when there is no partition (P), a system still faces a critical trade-off between latency (L) and consistency (C).
This introduced a second layer of decision-making:
If a partition occurs (P), the system must choose between Availability (A) and Consistency (C).
Else (E), even in normal operation, the system must choose between Latency (L) and Consistency (C).
For instance, large-scale cloud-native applications might prefer low latency over strict consistency, making PACELC a more practical model for real-world system design.
These theoretical models influenced modern distributed databases, helping architects make informed trade-offs between performance, availability, and consistency.
Rise of Multi-Primary Replication Protocols
As distributed applications grew in complexity, traditional single-primary replication models became a bottleneck. These systems relied on a single leader node to handle all writes, which introduced:
Scalability limitations – A single leader can become a bottleneck under heavy write loads.
Latency issues – Requests routed to a single primary can experience delays due to network hops.
Fault tolerance concerns – If the leader fails for any reasons, the system must elect a new primary, causing downtime.
To address these concerns, multi-primary replication protocols emerged. Unlike single-primary setups, these systems allow multiple nodes to accept write operations concurrently, significantly increasing throughput and availability.⚡
However, this approach introduced new challenges in maintaining consistency, such as:
Write Conflicts – Two nodes may modify the same data simultaneously, leading to diverging states.
Conflict Resolution – Systems must implement mechanisms like version vectors, quorum-based writes, or consensus algorithms (e.g., Paxos, Raft) to ensure correct synchronization.
Despite these challenges, multi-primary replication became a powerful solution for highly available distributed databases and global-scale applications like Google Spanner, Amazon Aurora, and CockroachDB.
Adoption of Hybrid Consistency Models
As distributed systems matured, it became clear that a one-size-fits-all consistency model was impractical. Some data operations required strong consistency, while others could tolerate eventual consistency. This realization led to the development of hybrid consistency models, where different data components follow different consistency guarantees.
For example, in a microservices-based e-commerce system:
Strong consistency is critical for inventory updates and payment transactions.
Eventual consistency is acceptable for user recommendations or analytics data.
Hybrid consistency models rely on techniques such as:
Conflict-Free Replicated Data Types (CRDTs) – Used in collaborative applications to merge concurrent updates.
Quorum-Based Writes (N/W/R configurations) – Ensures data consistency while maintaining availability.
Time-Based Conflict Resolution – Uses timestamps or version vectors to resolve conflicts.
By adopting context-aware consistency strategies, hybrid models allow systems to optimize for both performance and correctness.
AI-Powered Adaptive Consistency
Recent advancements in AI and machine learning have introduced adaptive consistency models, where systems dynamically adjust consistency settings based on real-time conditions. These models:
Monitor traffic patterns, network delays, and user behaviors.
Dynamically switch between strong and eventual consistency based on workload fluctuations.
Reduce latency by relaxing consistency guarantees when possible.
For instance, during peak traffic hours, an AI-driven system might:
✅ Relax consistency for non-critical data to improve performance.
✅ Increase consistency guarantees for financial transactions to ensure correctness.
These AI-based models align with the principles of CAP and PACELC, introducing a new level of automation and intelligence in balancing availability, consistency, and latency. While still in its early stages, AI-powered adaptive consistency is paving the way for next-generation distributed architectures.
From early distributed systems to CAP/PACELC theorems, from multi-primary replication to hybrid and AI-powered models, the evolution of consistency models reflects the constant trade-offs between performance, availability, and correctness.
As modern systems scale across cloud-native, edge computing, and global data infrastructures, consistency will remain a core challenge—but also a key differentiator in how we design scalable, resilient, and high-performance distributed applications.
🚀 Next, we explore how different distributed databases implement these models in practice!
How Eventual and Strong Consistency Fit into Microservices Architecture
Microservices architecture has profoundly reshaped how large and complex software applications are designed. In this architecture, applications are composed of smaller, independently deployable services.
Each service targets a single business capability, which allows teams to develop, run, and extend specific tasks without affecting other parts of the system. This approach has gained popularity among organizations seeking to improve flexibility and scalability in centralized environments.
However, because data is distributed across multiple services, maintaining consistency becomes critical (and it’s not so easy). Understanding how eventual and strong consistency fit into microservices will help architects select strategies that balance performance, reliability, and flexibility.
Defining Microservices and Their Core Principles
Microservices are based on encapsulating individual business processes into independent services that interact through simple contract interfaces. Each service also manages its own data storage and operations, minimizing the business overheads inherent in monolithic architectures.
The core principles of microservices include things like service autonomy, decentralization of governance, and the use of domain-driven design. These principles help accelerate development and deployment cycles.🌍
However, this massive freedom comes with challenges, particularly in terms of data synchronization. There must be clear strategies for handling synchronization issues, as service boundaries and data ownership must be well-defined.
By clearly identifying where each service's responsibilities lie, communication between services can be minimized, and each service can adopt the most appropriate consistency model for its specific use case.
The Role of Loose Coupling and Service Autonomy
Loose coupling refers to the design principle where services operate with minimal dependency on one another, allowing each to evolve at its own pace. This design promotes robustness since the failure of one service does not necessarily affect the entire system.
However, this loose coupling creates challenges in data consistency. Each service must independently manage its own consistency settings. Some services may use synchronous mechanisms to ensure strong consistency (e.g., ensuring data integrity with concurrent requests), while others may leverage asynchronous replication mechanisms to support eventual consistency.
In practice, microservices architectures may require a mix of consistency models: mission-critical services may demand high consistency to protect data, while less critical services can prioritize scalability over immediate consistency.
The architectural challenge is to avoid incompatibilities between communication protocols and data models across services, while still supporting a flexible approach to consistency.🔥
Why Consistency Becomes More Complex in Microservices
The complexity of maintaining consistency increases when data is distributed across multiple domains, each handled by a separate service. Transactional models commonly associated with monolithic architectures can become problematic in microservices, as updating multiple services (e.g., payment, ledger, and notification services in a financial application) may require complex coordination.
Some services might tolerate temporary inconsistency to prioritize throughput, favoring eventual consistency to improve performance. Others may demand strict consistency, requiring more rigorous conflict resolution mechanisms to ensure data integrity.
Consequently, microservices architectures require well-defined data contracts, reliable messaging mechanisms, and monitoring to address synchronization problems.
A hybrid approach that combines synchronous and asynchronous mechanisms can be employed, with high-accuracy services using synchronous interactions and less time-sensitive services relying on asynchronous communication.
Balancing Consistency and Scalability
A key goal of microservices is achieving horizontal scalability to accommodate growing transaction volumes. While strong consistency ensures correctness, it can limit scalability due to its reliance on synchronous coordination. This can lead to increased latency and contention in global environments, which can be problematic in distributed systems but less of an issue in localized setups.
Eventual consistency, on the other hand, uses asynchronous updates that improve system liveness and availability. However, this can introduce temporary data discrepancies, which may impact user experience and system performance.
Most microservices-based systems adopt a mixed approach where strong consistency is applied to transactional operations, while eventual consistency is used for non-critical or less time-sensitive operations. This strategy allows teams to reduce resource overheads while addressing business concerns effectively.
By prioritizing consistency requirements based on the needs of each domain, organizations can design systems that are both highly reliable and able to scale to meet varying loads. Ultimately, the selection of the appropriate consistency model is influenced by factors such as the performance requirements, data sensitivity, and the organization’s ability to manage added complexity.
Eventual Consistency Concepts
Eventual consistency is a distributed systems model where replicas of data are allowed to diverge temporarily, but will converge to the same state over time. This model allows data updates to propagate asynchronously across multiple nodes, rather than requiring immediate synchronization.
While this can lead to short-term inconsistencies, it ultimately guarantees that, given enough time and without new updates being made, all replicas will match the most current data. The key principles of eventual consistency are:
Asynchronous Updates: Updates are made to one replica, and then eventually propagated to other replicas at different times. This is contrary to the strict write quorum approach used in other consistency models, which require that all replicas be updated simultaneously.
Availability and Partition Tolerance: Based on the CAP theorem, eventual consistency prioritizes availability and partition tolerance, especially in large, distributed systems. Even if some nodes become temporarily unavailable, the system as a whole remains operational, as data may still be updated on other nodes without needing to immediately synchronize with the others.
Convergence: Over time, as updates are disseminated across the system, all replicas will eventually converge to the same consistent state, ensuring that all valid writes are eventually reflected across all nodes.
Conflict Resolution: Since updates are made asynchronously, conflicting changes can occur if two nodes update the same data concurrently. Systems must implement conflict resolution mechanisms to ensure that such conflicts are resolved without data corruption.
Examples in Microservices
In microservices architecture, two common approaches implement the concept of eventual consistency: Event Sourcing and Command Query Responsibility Segregation (CQRS).
Event Sourcing: This pattern stores the state of an entity as a series of events rather than as a single record. Each new event is appended to an event store, and other services can process these events asynchronously. This decouples the services, allowing them to process updates independently without needing to lock global resources. Over time, as events are processed, the state of the entity will converge across all services.
CQRS: This pattern separates read and write models, ensuring that each service has a specialized model for its task. In CQRS, the write side (command) updates data, while the read side (query) maintains a denormalized or materialized view that is updated asynchronously. We have to say it, this creates a slight delay between the time a write occurs and when it becomes visible to readers, but it reduces contention and enhances performance by allowing the query model to scale independently.
Benefits of Eventual Consistency
High Availability: Eventual consistency ensures high availability, even during network failures or temporary outages. Systems that use eventual consistency, like Amazon’s Dynamo, can continue functioning in the face of partitioned networks, where some nodes might be temporarily unreachable.
Scalability: Because updates are asynchronous, systems can scale more easily by adding new replicas without the overhead of coordinating global consistency. This aligns well with microservices architectures, where services can be scaled independently based on demand.
Elasticity: Eventual consistency provides elasticity by enabling systems to handle large amounts of traffic without the constraints of strict synchronization. This is particularly useful in unpredictable traffic scenarios, where load can spike without causing system failures.
Business Continuity: By ensuring that services remain responsive even during temporary infrastructure failures, eventual consistency supports business continuity, reducing the risk of disruptions during downtime or network issues.
Challenges of Eventual Consistency
While eventual consistency offers many benefits, it also introduces challenges, particularly in systems where immediate consistency is critical:
Temporary Inconsistencies: Since replicas are not immediately synchronized, there may be brief periods where data is inconsistent. This can be problematic in systems that require real-time, accurate data, such as financial or healthcare applications.
Conflict Resolution: Concurrent writes across replicas can lead to conflicts. The reconciliation of these conflicting updates can be complex and error-prone, requiring sophisticated conflict resolution mechanisms to ensure consistency without data loss or corruption.
User Experience: The delay in data updates can erode user trust, especially in applications where real-time accuracy is expected. End-users may perceive the system as unreliable if they encounter inconsistencies or delayed data, which can impact their confidence in the platform.
Complexity in Implementation: Implementing eventual consistency requires careful planning around conflict resolution, data reconciliation, and monitoring. Systems must provide clear signals to users when data may be stale and ensure that compensation mechanisms are in place to prevent confusion or data errors.
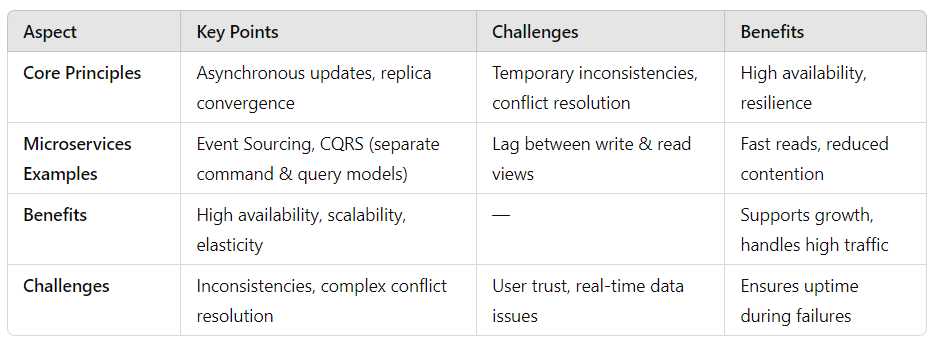
By adopting eventual consistency where appropriate, microservices architectures can ensure that systems remain responsive, scalable, and resilient to failures, while addressing the trade-offs between consistency and performance in distributed environments.
Conclusion
As distributed systems evolved, the challenge of maintaining data consistency across multiple nodes became a critical concern. Unlike monolithic architectures, microservices distribute data across independent services, introducing trade-offs between consistency, availability, and scalability. Strong consistency ensures correctness but often limits performance, while eventual consistency prioritizes responsiveness and fault tolerance at the cost of temporary data inconsistencies.✅
In microservices architectures, balancing these consistency models depends on domain-specific requirements. Eventual consistency, implemented through patterns like Event Sourcing and CQRS, enhances system resilience and scalability, making it well-suited for high-traffic and loosely coupled environments. However, applications that demand real-time accuracy, such as financial or healthcare systems, must carefully mitigate inconsistencies through conflict resolution and user experience strategies.
Ultimately, architects must assess business needs, performance constraints, and operational risks when choosing consistency mechanisms. A well-designed microservices system strategically blends strong and eventual consistency to optimize for both correctness and agility, ensuring that services remain reliable and efficient in distributed environments.
In the next section of this Ninth Part, we will explore the specifications of strong consistency mechanisms, diving into their key principles, trade-offs, and real-world applications. Expect detailed insights, practical use cases, and comparisons to help you understand when and how to apply strong consistency in microservices architectures.